
(Last Mod: 28 November 2010 00:06:12 )
NOTE: WORK VERY MUCH IN PROGRESS
Bookmarks on this page
Links to other pages
Radio Testbed
Concurrent codes are a form of superimposed codes that can be decoded efficiently. It turns out that this property enables the development of a new form of spread spectrum radio communication that offers new ways to address several problems. The key ones that have been identified to date include:
Unkeyed jam resistance in adversarial environments.
Jam resistance in public-access networks.
RFID self-jamming.
MAC (Media Access Control) protocol simplification in wireless networks.
Clock recovery and synchronization.
Before we delve into a bunch of theory about what concurrent codes are and how they do what they do, let's briefly look at each of these problems to get a feel for the kinds of things that we hope to accomplish using concurrent codes.
Presently the only means of providing a measure of jam resistance to an omni-direction radio signal is through the use of some form of spread spectrum, such as frequency hop or direct sequence. However, presently these all require that the specific function used to spread the spectrum, such as the hop sequence used by frequency hop systems or the chip sequence used by direct sequence systems, be a well-protected secret that is shared between the legitimate senders and receivers. If the enemy gains knowledge of the spreading code, then nearly all jam resistance is lost.
Such shared secrets are referred to as "symmetric keys" because both parties must have the same information. Even in small networks (a dozen or so radios), the necessary symmetric key management and distribution procedures frequently cause problems in getting the radios all configured properly. The result when this happens is either that the mission must be delayed, aborted altogether, or carried out with any communications performed 'in the clear".
As networks grow to include thousands and, potentially, even millions of nodes (as might be the case with emplaced sensor networks), the symmetric key management and distribution problem can be expected to quickly pose a major barrier to being able to grow the networks to the desired size. However, if a form of jam resistance could be found that either relied on asymmetric keys (each party uses different keys, only one of which much be kept secret), or no secret keys as all, then the key management hurdle for large networks because enormously more tractable.
Even if the management and distribution of symmetric keys were not a major issue, there are several systems that, by their very nature, would not permit the use of secret keys since everyone, including any hostile parties, are authorized users of the system. Perhaps the most stark example of such a system is civilian GPS. This system uses direct sequence spread spectrum and therefore has a specific chip sequence in use. However, every receiver has to have access to this information in order to function and since everyone on the planet is an authorized user of the system, the information is publicly available and, thus, civilian GPS has no protection against hostile jamming from someone that is willing to exploit knowledge of the chip sequence in designing their jamming waveform.
However, if a form of spread spectrum could be developed that retained a level of jam resistance comparable to a shared-secret system but that did not require the shared secrets to do so, then public access systems, like civilian GPS, could receive a level of jam resistance comparable to that enjoyed by military GPS.
(ADD NEW INTO PARAGRAPH)
guarded
that dispenses with the pre-shared secret keys previously needed for the physical layer if an omni-directional transmission was to have any significant resistance to hostile jamming. This is advantageous because managing such keys -- known as symmetric keys -- is a major limiting factor in scaling up wireless networks to the size needed for Network Centric Operations, particularly in the highly dynamic, mobile environments typical of a tactical theatre.
It's self-evident that when one side of a conflict uses a wireless communications network to conduct operations in the vicinity of an adversary, that the adversary will benefit if they can disrupt that network. There are many ways to cause this disruption and one of the most obvious (and the one we are concerned with here) is to simply jam the radio signal that is carrying the network information.
No communication system is jam-proof -- if the enemy is able and willing to commit sufficient energy to jam a communications channel, they will succeed. Hence, the goal of a jam-resistant communication system is not to make it impossible for the enemy to jam it, but merely to raise the effort required beyond that at which the enemy is able and willing to operate. For example, a jam-resistant technology might increase the energy needed to a point such that their equipment simply can't put out the needed power or their power source, particularly if the jammers are battery operated, can't last long enough to be effective. But even if they are technically capable of operating at higher power, they may not be willing to -- as they increase their power output they make it more likely that the defenders will be able to locate and neutralize them.
There are presently two ways to improve the jam-resistance of a radio signal: (1) use highly directional antennas, or (2) use spread spectrum. In situations, which are many, where directionality cannot be used to obtain jam resistance, we must look to spread spectrum techniques to provide it. However, simply using spread spectrum does not ensure jam-resistance. In traditional spread spectrum communications, the jam resistance comes from using information to spread, and later despread, the signal that the legitimate parties possess but that the adversaries lack. This information, principally the "spreading code", constitutes a shared-secret and since all of the legitimate parties have to have the same information, it is also known as a "symmetric key".
The problem with symmetric keys is that they are very difficult to manage, especially on a large scale. First, a means must be devised to distribute the same key to multiple parties, who may be located far and wide, while ensuring that it doesn't fall into hostile hands in the process. Second, the more people have a given key, the more likely it is that it will fall into hostile hands even once it has been successfully distributed and, even worse, that this will go undetected. Both of these vulnerabilities can be mitigated by reducing the number of people that have a given key and also limiting how long that key remains valid. Unfortunately, reducing the number of people that have a given key means increasing the overall number of keys in use, and reducing the amount of time that keys are valid means increasing the frequency at which new keys must be generated and distributed. The net effect is that the use of spread spectrum systems that rely on symmetric keys for jam resistance is only practical for relatively small networks and does not scale well to the type of large, ad hoc mobile networks that are emerging.
The field of cryptography once faced a similar conundrum and the vibrant online commerce industry that exists today would not be possible if an alternative to symmetric keys had not been found. Fortunately, the mid-1970's saw the development of asymmetric cryptography in which the two parties involved in a communication can use different keys: only one of these keys, the private key, has to be kept secret and it never has to be shared with anyone. The other key, the public key, has to be distributed to the other party but there is no requirement that it remain secret. Unfortunately, the use of public-private keys to secure communications requires that communications, even if insecure, still be possible in the first place. No one has yet devised a means of using asymmetric keys as a means for providing jam-resistance to a radio link.
However, in 2007 researchers from the Academy Center for Information Security (ACIS), located within the Department of Computer Science (DFCS) at the U.S. Air Force Academy (USAFA), devised a means of providing jam-resistance to a radio link without using any keys at all or, to be perhaps more accurate, by only using public keys (i.e., no private keys, or secrets, of any any sort). The basic approach used by the ACIS researchers was to assume that both the legitimate sender and the attacker were equally capable of formatting and transmitting legitimate radio signals and that the attacker could time their transmissions so as to have both arrive at the intended receiver simultaneously. Such a hostile waveform is sometimes referred to as the perfect jamming signal since, with all traditional modulation and encoding schemes, this will result in a signal so corrupt as to be indecipherable even if the power in the hostile signal is significantly less than that in the legitimate signal. However, by exploiting the asymmetry in certain modulation schemes (as opposed to asymmetry in the keys), an encoding scheme was developed that allows a receiver to recover both signals. This encoding scheme is based on a new field of coding theory known as "concurrent codes" and the sole existing algorithm for implementing it is known as "BBC".
With a BBC-encoded radio link, a receiver can successfully receive multiple messages sent concurrently and its output is simply a list of all such messages, whether they originate from a legitimate sender or from an attacker. Because the system assumes that the attacker has all of the information that the legitimate sender has (as far as the physical layer radio link is concerned), the receiver has no way to discriminate against the attacker's signal. However, the system as a whole does. Just because asymmetric keys can't be used to protect the physical signal does not mean that they can't be used to protect the data transmitted using that signal. In particular, public-private keys can be used both to encrypt the transmitted data and to digitally sign the data so as to permit authentication of it. The one thing that is sacrificed, compared to a traditional symmetric-keyed spread spectrum system, is low probability of detection. Since the attacker must be assumed to know all of the physical layer radio link parameters that the legitimate receiver does, reception of the signal is equally possible for either of them.
From here, we will provide an introduction to the properties of superimposed codes, which date back at least to the mid-1950's, and show how they can be used to construct, in principle, a jam-resistant coding scheme that uses only public keys. In doing so, we will also show that the decoding complexity associated with traditional codes make them unsuitable for use in implementing such a system in practice. We will then proceed to show how a suitable code, called a concurrent code, can be constructed and how the resulting algorithm, the BBC algorithm, can be used to implement a practical keyless jam-resistance system.
The codes we will be working with are "block codes", meaning that a fixed-length block of data bits is mapped to a fixed-length block of code bits. We will call the block of data bits the "message" and the block of code bits the "codeword". For convenience, we will number the bits in each from left-to-right starting with bit 0.
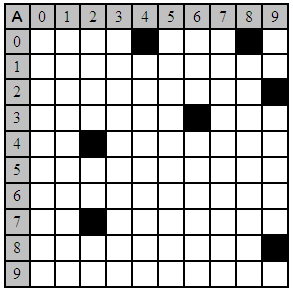
Because the codewords we will be working with tend to be large and sparse (i.e., mostly 0's with only a few 1's), we will represent them visually. Imagine taking a codeword whose length is chosen to be RxC and organizing it into R groups of bits with C bits per group. Now, instead of writing the codeword on a single line of text we simply write it on R separate lines with one group per line. We end up with an RxC rectangular array of bits, which we can convert to a picture by simply coloring the pixels in an RxC bitmap white if the corresponding bit in the codeword is a zero (which we will call a "space") and black if the corresponding codeword bit is a one (which we will call a "mark"). The upper left corner pixel in the picture thus corresponds to bit 0 and the lower right corner pixel corresponds to the last bit, bit (RC-1).
To make this clearer, consider a toy problem in which our codebook contains 32 codewords and, hence, there are only 32 possible messages we can send. For simplicity, we will label the first twenty-six messages 'A' though 'Z' and the last six messages '1' though '6'. The codeword for each message will be 100 bits long, which we can represent as a 10x10 image. Each codeword will have seven marks randomly placed in it. For example, the codeword for message 'A' has marks at locations {04,08,29,36,42,72,89} while the marks in the codeword for message 'K' are at {2,16,26,30,36,57,94} and those for 'Q' are at {6,14,19,27,33,63,81}. These are shown visually below:
|
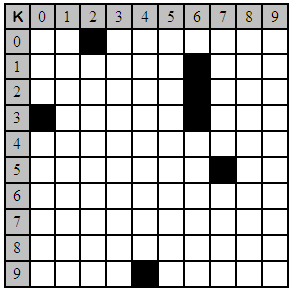
With this information at hand, determine which of the above messages are and are not contained in the received packet shown below.
|
With some careful examination, you should discover that the packet contains all of the marks needed to cover messages 'A' and 'Q', but that it lacks one of the marks, namely the one at position 57, needed to cover message 'K'. Thus this packet contains messages 'A' and 'Q', but not 'K'.
Before we proceed further, let's consider the potential implications of what we already have. What if a legitimate sender wanted to transmit message 'A' and formed the codeword for that message and then broadcast it? What if a hostile jammer, knowing that the optimal jamming signal is another legitimate signal overlaid on the first, formed the codeword for the message 'Q' and broadcast it in such a way that it perfectly lined up, at the receiver, with the signal from the legitimate sender. Normally such a situation would leave both signals hopelessly corrupted, but in this case the receiver was able to recover both messages -- the jammer failed to jam the channel, even with an optimal jamming signal.
But it isn't time to celebrate yet -- there are two big issues that need to be addressed before we can begin constructing a practical jam-resistant communications system around what we already have. The first stems from the fact that the messages that were recovered were done so by specifically looking for those messages. But since, in general, we don't know what message(s) may have been transmitted, we need to be able to efficiently decode a packet to generate a list of all of the messages it contains. The second is that, in order to recover one message even in the presence of the other, two signals had to combined in a way such that marks are, in effect, indelible. In other words, a message remains recoverable only as long as all of the marks in it remain marks. If the attacker has the ability to erase any of a codeword's marks, then that codeword is removed from the packet. What is required is that the communications be an "additive-OR" channel. These issues will be explored in the next two sections.
Let's continue with the example from the previous section. We know that messages 'A' and 'Q' are in the packet, and also that the message 'K' is not. But what about the remaining 29 possible messages? Are any of them covered as well? Which ones? How could we determine this?
The obvious answer is that we would need to know the patterns for all of the remaining 29 messages and then we could examine each one in turn to see if the received packet covered it. The process of checking if a particular message is covered by the packet is referred to as performing a "membership test" on that message. Thus, with what we know so far, to "decode" a given packet (determine all of the messages covered by that packet) we would need to perform a membership test on every entry in the codebook.
The codes we have been working with up to this point are known as "superimposed" codes and the codewords are generally constructed using algorithms that are designed to guarantee certain properties. Unfortunately, these properties generally aim to make each codeword as independent from all of the others as possible and the result is that decoding a packet would generally involve the type of exhaustive, brute force membership span of the entire potential codebook space that has just been described. Thus, historically, superimposed codes have only been used in applications where either the codebook is quite small or in which the only interest is in performing membership tests on a limited set of possible messages. As an example of the latter, consider forming a codeword for every word in the dictionary and then combining them into a single packet. If used as part of a spell checking program, all that is required to spell check a document is to perform a membership test on each word in the document, which would represent a reasonable amount of work. However, if it was also necessary to be able to decode, even partially, the packet to recover the words within it, then this would be intractable. For instance, in order to retrieve all of the eight letters words that start with the letter 'P', membership tests on over eight billion possible words would have to be performed. To produce a list of all words that are ten characters or less would require over 140 trillion membership tests.
But what if we constructed our codebook in such a way that we gave up a significant amount of the independence between codewords in exchange for sufficient structure so as to make decoding efficient? For instance, what if we required that all messages sharing a common prefix must share a common subset of marks in their corresponding codewords? The implication is that if any of the marks associated with a given prefix is absent from the packet, then none of the messages that share that prefix will be covered by that packet and we need not look for them.
Building such a codebook is trivially simple -- all that is needed is a hash function that, given a message prefix, generates a value that can be interpreted as a position within the codeword. Our present example, with its 100 bit codewords, requires a hash function that returns a value between 0 and 99 (inclusive). Once we have such a hash function we can generate any codeword we need to by simply running all of the message prefixes through the hash function and collecting the results.
Recall that our present example has thirty-two messages but that our codewords have seven marks in them, even though only five bits of information are required to enumerate all thirty-two of our messages. The additional two marks come from extending, or padding, each message with two additional bits, both set to zero, and encoding the padded message according to the process already described. We'll discuss the purpose served by these additional marks shortly.
So let's encode the message 'K' to see how this works. This message is the eleventh message in the codebook so the binary pattern associated with it is 0101000. Running the seven prefixes through the hash function yields the results shown below.
H('0') = 36
H('01') = 57
H('010') = 16
H('0101') = 02
H('01010') = 26
H('010100') = 30
H('0101000') = 94
Gathering these together and sorting them (for our convenience) we get that the codeword for message 'K' is {2,16,26,30,36,57,94}, which matches the list we originally started with. Enumerating the complete codebook for our toy example, we have:
| 36 | 89 | 08 | 04 | 42 | 72 | 29 | A | 0000000 |
| 82 | 46 | 64 | B | 0000100 | ||||
| 28 | 18 | 48 | 25 | C | 0001000 | |||
| 62 | 36 | 88 | D | 0001100 | ||||
| 91 | 52 | 49 | 01 | 45 | E | 0010000 | ||
| 79 | 71 | 38 | F | 0010100 | ||||
| 13 | 03 | 56 | 12 | G | 0011000 | |||
| 98 | 53 | 22 | H | 0011100 | ||||
| 57 | 16 | 40 | 37 | 47 | 50 | I | 0100000 | |
| 92 | 30 | 76 | J | 0100100 | ||||
| 02 | 26 | 30 | 94 | K | 0101000 | |||
| 78 | 61 | 32 | L | 0101100 | ||||
| 59 | 22 | 75 | 15 | 80 | M | 0110000 | ||
| 85 | 20 | 40 | N | 0110100 | ||||
| 43 | 31 | 99 | 36 | O | 0111000 | |||
| 18 | 67 | 93 | P | 0111100 | ||||
| 27 | 19 | 63 | 81 | 14 | 33 | 06 | Q | 1000000 |
| 04 | 87 | 41 | R | 1000100 | ||||
| 46 | 10 | 58 | 66 | S | 1001000 | |||
| 69 | 51 | 08 | T | 1001100 | ||||
| 11 | 07 | 83 | 76 | 28 | U | 1010000 | ||
| 54 | 13 | 17 | V | 1010100 | ||||
| 35 | 09 | 57 | 73 | W | 1011000 | |||
| 44 | 39 | 24 | X | 1011100 | ||||
| 23 | 49 | 11 | 86 | 60 | 05 | Y | 1100000 | |
| 19 | 53 | 84 | Z | 1100100 | ||||
| 72 | 00 | 12 | 46 | 1 | 1101000 | |||
| 67 | 52 | 61 | 2 | 1101100 | ||||
| 90 | 24 | 79 | 31 | 99 | 3 | 1110000 | ||
| 44 | 71 | 18 | 4 | 1110100 | ||||
| 96 | 25 | 01 | 56 | 5 | 1111000 | |||
| 68 | 88 | 39 | 6 | 1111100 |
So let's decode the packet used previously and see the entire list of messages it contains.
|
PACKET =
{
02,04,06,08,10,11,14,16,19,22,23,26,27,29,30,33,36,42,44,45,47.48,49,
51,53,56,59,60,61,63,65,67,68,72,78,81,84,86,89,90,93,94,97,98
}
Instead of checking each of the thirty-two possible messages by brute force examination, we will exploit the structure of the codebook and recover the messages that are covered incrementally, one message bit at a time. To start with, if there are any messages contained in the packet at all, then the first (left-most) bit is either a 0 or a 1. If any messages start with a 0, then a mark will exist in the packet at H('0')=36, while if any messages start with 1, there will be a mark at H('1')=27. Since both marks are present, our initial list of possible messages is:
Message List = {0,1}
At any given time, the message list consists of all "prefixes" that are consistent with the set of padded messages that might be covered by the packet. Since any possible message either has a 1-bit prefix of '0' or '1', we have not narrowed down the range of possibilities yet. As long as there are any possibilities, i.e., the message list is not empty, we will proceed to decode the list of prefixes that are one bit longer than what we presently have in our list.
So we must check for marks in the following locations:
| Prefix | Location | Found? |
| 00 | 89 | Y |
| 01 | 57 | N |
| 10 | 19 | Y |
| 11 | 23 | Y |
Since the mark for prefix 01 was not found, we can prune it from the list (or simply not add it) and do not need to look further for any padded messages that begin with this prefix. Our message list is now:
Message List = {00,10,11}
The iterations over all of the prefix lengths would produce the following message lists after each stage:
1-bit prefixes: {0, 1}
2-bit prefixes: {00, 10, 11}
3-bit prefixes: {000, 100, 101, 110, 111}
4-bit prefixes: {0000, 1000, 1100, 1101}
5-bit prefixes: {00000, 10000, 10001, 11000, 11001, 11011}
6-bit prefixes: {000000, 100000, 110000, 110010}
7-bit prefixes: {0000000, 1000000, 1100100}
At this point we can strip the padding from the padded messages and convert them into the actual messages which, in this case, are 'A' , 'Q', and 'Z'.
To get a different view of the decoding process, let's take the codebook and shade every mark we needed to actually look at and strike through any marks that we looked for and did not find.
| 36 | 89 | 08 | 04 | 42 | 72 | 29 | A | 0000000 |
| 82 | 46 | 64 | B | 0000100 | ||||
| 28 | 18 | 48 | 25 | C | 0001000 | |||
| 62 | 36 | 88 | D | 0001100 | ||||
| 91 | 52 | 49 | 01 | 45 | E | 0010000 | ||
| 79 | 71 | 38 | F | 0010100 | ||||
| 13 | 03 | 56 | 12 | G | 0011000 | |||
| 98 | 53 | 22 | H | 0011100 | ||||
| 57 | 16 | 40 | 37 | 47 | 50 | I | 0100000 | |
| 92 | 30 | 76 | J | 0100100 | ||||
| 02 | 26 | 30 | 94 | K | 0101000 | |||
| 78 | 61 | 32 | L | 0101100 | ||||
| 59 | 22 | 75 | 15 | 80 | M | 0110000 | ||
| 85 | 20 | 40 | N | 0110100 | ||||
| 43 | 31 | 99 | 36 | O | 0111000 | |||
| 18 | 67 | 93 | P | 0111100 | ||||
| 27 | 19 | 63 | 81 | 14 | 33 | 06 | Q | 1000000 |
| 04 | 87 | 41 | R | 1000100 | ||||
| 46 | 10 | 58 | 66 | S | 1001000 | |||
| 69 | 51 | 08 | T | 1001100 | ||||
| 11 | 07 | 83 | 76 | 28 | U | 1010000 | ||
| 54 | 13 | 17 | V | 1010100 | ||||
| 35 | 09 | 57 | 73 | W | 1011000 | |||
| 44 | 39 | 24 | X | 1011100 | ||||
| 23 | 49 | 11 | 86 | 60 | 05 | Y | 1100000 | |
| 19 | 53 | 84 | Z | 1100100 | ||||
| 72 | 00 | 12 | 46 | 1 | 1101000 | |||
| 67 | 52 | 61 | 2 | 1101100 | ||||
| 90 | 24 | 79 | 31 | 99 | 3 | 1110000 | ||
| 44 | 71 | 18 | 4 | 1110100 | ||||
| 96 | 25 | 01 | 56 | 5 | 1111000 | |||
| 68 | 88 | 39 | 6 | 1111100 |
The key thing to note is that each mark that is looked for and not found eliminates one or more messages from possible consideration. If this happens early in the decoding process, many potential messages are eliminated all at once.
At this point we can see the purpose of the extra '0' bits that are appended to each message before encoding it. It's true that the first five bits are sufficient to associate a set of (hopefully unique) marks with a particular message. But let's consider what would have happened had we stopped after examining just the first five prefixes. At that point the messages 'R', 'Y', and '2' were still in the list and would have become messages we would have concluded were covered by the packet. However, this was not the case and these messages would have been "false hits" which, in the vernacular of concurrent codes, are called "hallucinations" because they are messages that appear to be genuine but don't really exist.
Recall that we sacrificed the independence of the codewords in order to impose a structure that permits efficient decoding. If our codebook only used the minimum number of marks needed to encode a message, then we would have sacrificed too much independence and would have set ourselves up for numerous hallucinations since every legitimate message would provide all of the marks except one for the neighboring message and we would only need a bit of noise (no pun intended) to generate the additional mark needed to throw a hallucination. In the the case of 'R', we wouldn't have even needed any noise - the additional mark needed in location 04 was provided by the codeword 'A'. Hence any packet containing 'A' and 'Q' would always produce 'R' as a message whether it was actually included or not. By tacking on two additional zeros to the codeword value, we have three locations in the codeword that are determined solely by that particular message. For a message not explicitly added to the packet, the probability that all three marks will exist in the packet because of noise or coincidental collisions with the marks in other packets is fairly small and, more importantly, can be made arbitrarily small simply by adding more zero bits to the codeword. Each zero bit acts as a checksum bit because it places a mark into the packet at a location that is a function of the entire message, just as the value of the checksum added to a message in a traditional coding scheme is affected by every bit in the message.
While concurrent codes permit packets of superimposed messages to be efficiently decoded into a list of all of the messages contained by the packet, they require that the physical channel within which the signals are combined possess a very specific property, namely that any signal that is added to a channel on top of those already there only has the ability to add marks and never to remove them. This property is very much at odds with the types of modulation schemes favored by modern communications systems, which generally strive for a "binary symmetric channel" in which the probability of experiencing an error that turns what what supposed to be a 1 into a 0 is the same as that of experiencing an error that turns a 0 into a 1. The reason, in loose terms, for wanting such a channel is that in most, if not all, modern communication systems an encoding is used in which the penalty suffered by either type of error is equivalent. Under such conditions, adjusting the system parameters so that both types are equally likely results in the lowest attainable overall bit error rate.
However, when concurrent codes are used to encode the data, the situation is radically different. The system can operate with very little degradation even if large numbers of spaces (0's) are turned into marks (1's), known as space errors. The same is not true in the event of mark errors (where a mark (1) is erroneously turned into a space (0)). As described thus far, a single mark error when decoding a message prefix will result in all messages sharing that prefix being lost. Thus the type of channel that is needed for concurrent coding to be successful is a highly asymmetric one in which space error rates approaching 50% can be tolerated, but in which mark error rates must be driven to near zero. An additive-OR channel has the kind of error asymmetry that is needed because in this type of channel signals are combined using a logical ORing of all the signals in the channel. The receiver detects a mark if any station, either friend or foe, is transmitting a mark while it detects a space only if no station, neither friend nor foe, is transmitting a mark.
Modifications to the BBC algorithm permit space error rates well above 50% to be tolerable and other modifications permit non-zero mark error rates to be tolerated. While we will save discussion of these extensions till later; the point to be taken at this juncture is that we do not require a perfect additive-OR channel, just a reasonable approximation of one. So the question that must be answered at this stage is whether modulation schemes that have the necessary bit error rate asymmetry are realizable.
To answer this question, let's consider the basic functionality of a radio transmitter and receiver when working with binary signals. At any given time the transmitter is either broadcasting a mark or a space by injecting some type of energy into the RF spectrum. The receiver, which detects energy within some portion, or bandwidth, of the RF spectrum, will sense some combination of signals from all sources, including the random noise within its own circuitry, and must decide whether the transmitter was more likely transmitting a mark or a space. In most modern modulation schemes the transmitter broadcasts one type of signal for a mark and another type of signal for a space and the receiver must decide if the waveform it received looks more like the first or the second. As noise and interfering signals increase in intensity, relative to the legitimate signal, the difficulty of making this decision increases and, at some point, the received signal looks so little like either a mark or a space that the receiver is effectively making random guesses when deciding its output. Worse, in the case of a hostile jammer, the interfering signal can be crafted so as to force the receiver to make a decision based almost entirely on the jammer's signal in which case the legitimate signal goes effectively unseen.
However, consider the case of old-fashioned OOK (On-Off Keying). In an OOK system, the transmitter remains silent (or, seen another way, broadcasts a signal having zero energy) when transmitting a space, but broadcasts a signal having non-zero energy when transmitting a mark. The receiver in this case could be nothing more than a simple radiometer (which measures the total energy present within the bandwidth of interest during each bit interval) and makes its decision based on whether the amount of energy detected is above or below its detection threshold. In most systems, the threshold is set high enough so that the probability of making a mark error is about the same as that of making a space error. But if the threshold is set low enough, a very high error rate asymmetry can be established in which it become highly unlikely that a mark error will be made, although space errors will become common. In theory, a jammer could broadcast a signal that "cancels out" enough of the signal transmitted by the legitimate sender (when sending a mark) that they could force a mark error. In practice, however, this is exceeding difficult to do since the signal has to be just the right shape, amplitude, and phase and it has to be this at the receiver's antenna. Even if the signal for a mark is nothing more than a pure sinusoid this is difficult to manage (except as a very transient effect). However, mother nature can frequently do a better job of this in what are known as high fading environments. But if the legitimate sender is broadcasting a very noisy signal, then the odds of either a jammer or mother nature pulling this off essentially vanish (unless the signal itself is so heavily attenuated as to be undetectable).
So our first realization of an additive-OR channel will use OOK modulation in which a noisy burst of energy with as much peak power as possible is used to transmit a mark and we will squelch the transmitter altogether when transmitting a space. Because our codewords are extremely sparse, perhaps one mark per thousand or more spaces, the average transmitted power will be very small. Thus, in theory, a transmitter could dump hundreds of watts of power into each mark while consuming less than a single watt on average. The receiver's detection threshold will be set low enough so that the output of the receiver is about one-tenth to one-third marks, which will result in the mark error rate nearly as low as it can get without exceeding the acceptable space error rate.
1 Definition of "superimposed code": http://www.nist.gov/dads/HTML/superimposedCode.html (27 Oct 07)
